

Architecture
参考文档: https://grafana.com/blog/2018/12/12/loki-prometheus-inspired-open-source-logging-for-cloud-natives/

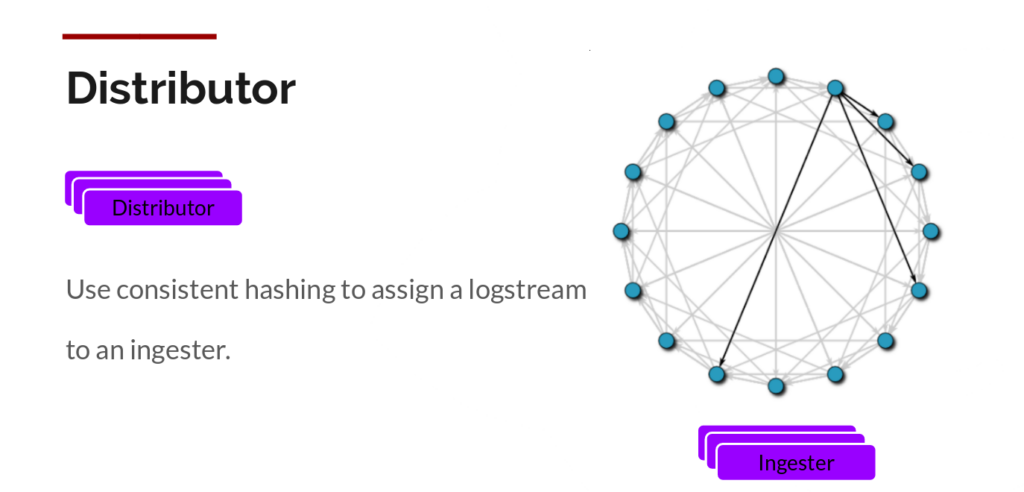
Distributor
一旦promtail收集并发送日志到Loki,分发器就是第一个接收日志的组件。现在我们每秒可能会收到数百万次写入,我们不想在日志到达时就将它们写入数据库。那样会毁掉任何数据库。我们需要在数据到达时对其进行批处理和压缩。
我们通过在日志到达时使用gzip压缩数据块来实现这一点。Ingester组件是一个有状态的组件,负责构建并刷新数据块。我们有多个Ingester,每个流的日志最终都应该位于同一个Ingester中,以便所有相关条目最终都位于同一个块中。我们通过构建一个Ingester环并使用一致性哈希来实现这一点。当一个条目到达时,Distributor 会对日志的标签进行哈希处理,然后根据哈希值查找要将该条目发送到哪个Ingester。
Ingester
现在,摄取器将接收条目并开始构建块。
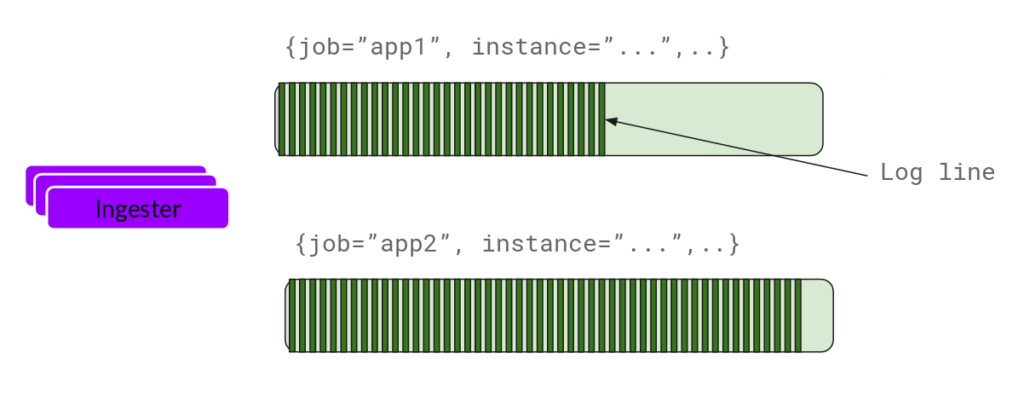
基本上就是将日志进行压缩并附加到chunk上面。一旦chunk“填满”(数据达到一定数量或者过了一定期限),Ingester 就将其刷新到数据库。我们为块和索引使用单独的数据库,因为它们存储的数据类型不同。

刷新数据块后,采集器会创建一个新的空数据块,并将新条目添加到该数据块中。
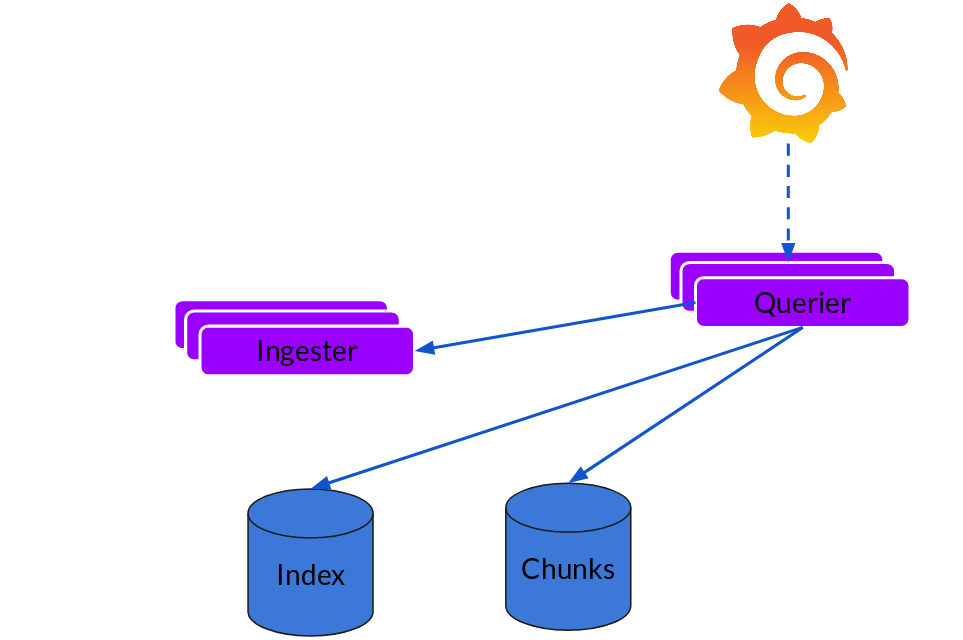
Querier
读取路径非常简单,查询器承担了大部分繁重的工作。给定一个时间范围和标签选择器,它会查看索引,找出匹配的块,然后对其进行 grep 操作,返回结果。它还会与数据采集器通信,获取尚未刷新的最新数据。
Write Path: Distributor 和 Ingester
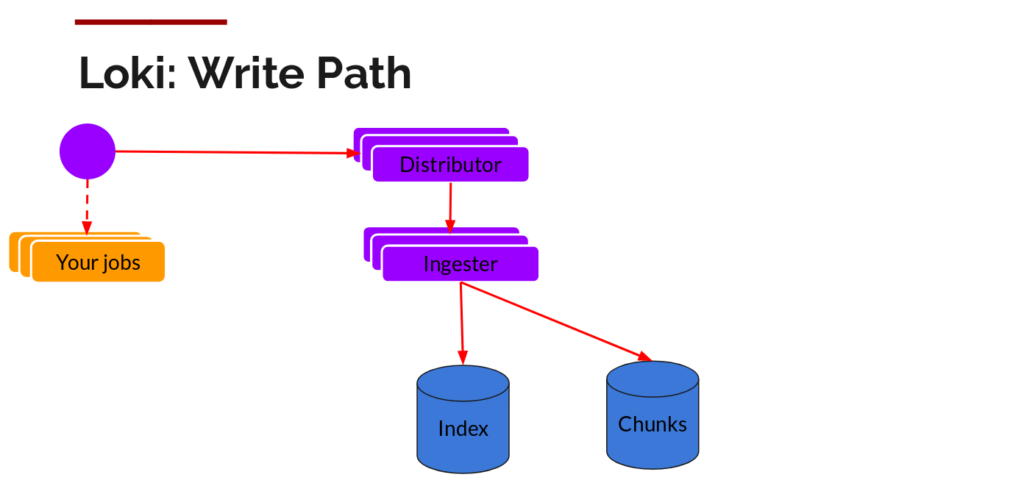
主要职责:
- Distributor 主要职责:做标签哈希、负载均衡、请求分发,不做任何数据持久化或数据块构建/压缩相关工作。它收到客户端(如 Promtail, Fluentd, Logstash)推来的日志流,将日志分发给一个或多个 Ingester。
- Ingester 主要职责:负责批量聚合日志,为每条日志分配 chunk(数据块),并管理 chunks 的最大大小/最大持续时间,最终在 chunks 刷新/关闭/持久化之前进行压缩。
- 为什么在 Ingester 端做:
- 只有 Ingester 有足够的上下文(chunk 何时合并/刷新),可以控制压缩时机和粒度。
- Gzip 压缩是 IO 密集型的,无需在流量分发层(分发器)浪费资源。
- 压缩常常与持久化(flush)动作绑定,通常同步写入云存储后端。
典型数据流回顾
- Promtail 发往 Distributor(分发器)。
- Distributor 对标签做一致性哈希,挑选 Ingester,并把日志行转发过去。
- Ingester 将日志行按流聚合到 chunk,写 chunk 时,进行压缩(通常默认用 Snappy,也支持 Gzip)。
- chunk 达到阈值后,flush 到后端存储(如 S3),存储格式为压缩块。
留言