

Architecture
Reference Documentation: https://grafana.com/blog/2018/12/12/loki-prometheus-inspired-open-source-logging-for-cloud-natives/

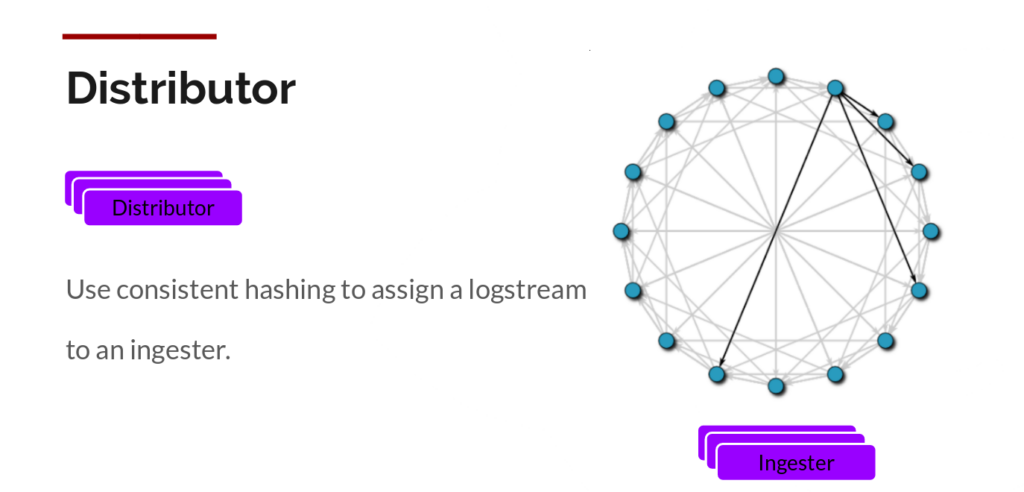
Distributor
Once promtail collects and sends the logs to Loki, the distributor is the first component to receive them. Now we could be receiving millions of writes per second and we wouldn’t want to write them to a database as they come in. That would kill any database out there. We would need batch and compress the data as it comes in.
We do this via building compressed chunks of the data, by gzipping logs as they come in. The ingester component is a stateful component in charge of building and then later flushing the chunks. We have multiple ingesters, and the logs belonging to each stream should always end up in the same ingester for all the relevant entries to end up in the same chunk. We do this by building a ring of ingesters and using consistent hashing. When an entry comes in, the distributor hashes the labels of the logs and then looks up which ingester to send the entry to based on the hash value.
Ingester
Now the ingester will receive the entries and start building chunks.
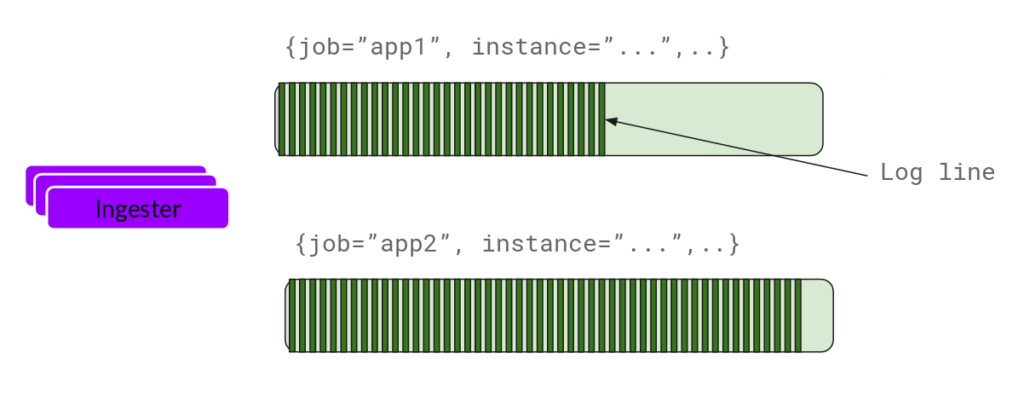
This is basically compressing the log and appends it to the chunk. Once the chunk is “fills up” (either by a certain amount of data or by a certain age), the ingester flushes it to the database. We use separate databases for chunks and indexes because they store different types of data.

After flushing a chunk, the ingester then creates a new empty chunk and adds the new entries into that chunk.
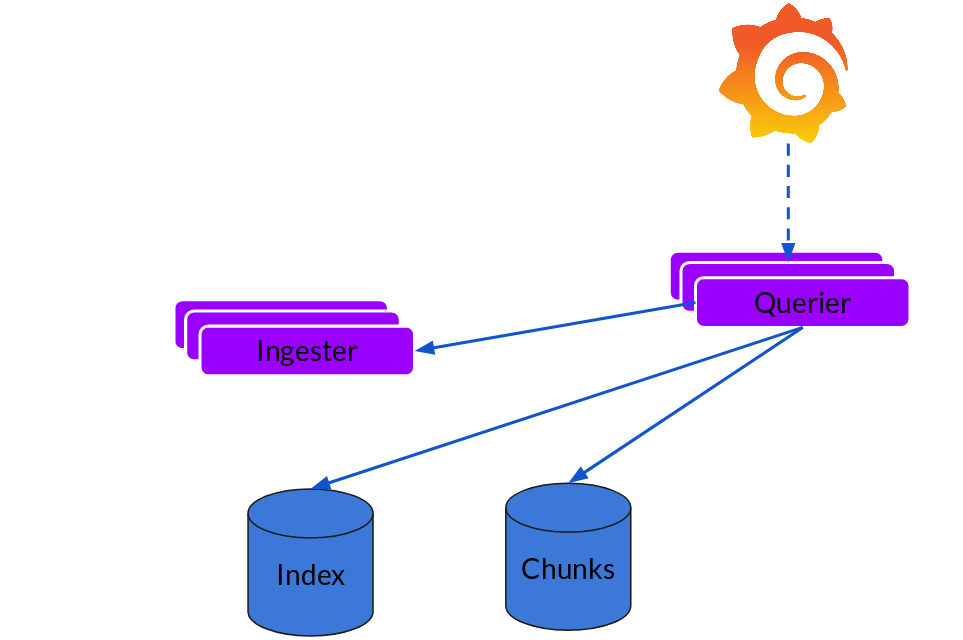
Querier
The read path is quite simple and has the querier doing most of the heavy lifting. Given a time-range and label selectors, it looks at the index to figure out which chunks match, and greps through them to give you the results. It also talks to the ingesters to get the recent data that has not been flushed yet.
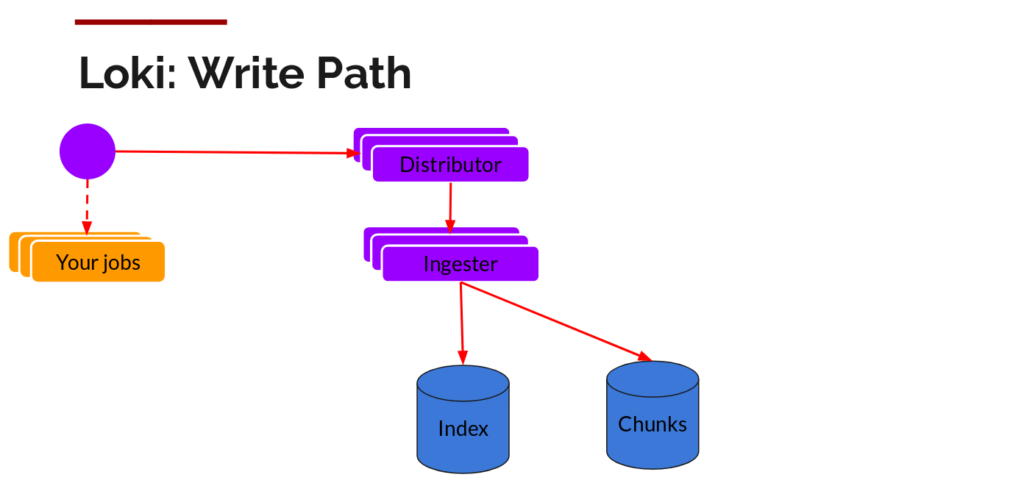
Write Path: Distributor And Ingester
Main Responsibilities:
- Distributor: Performs tag hashing, load balancing, and request distribution. Does not perform any data persistence or chunk building/compression. It receives log streams from clients (such as Promtail, Fluentd, and Logstash) and distributes them to one or more Ingesters.
- Ingester: Aggregates logs in batches, assigns chunks to each log record, manages the maximum size and duration of chunks, and ultimately, compresses chunks before flushing, closing, or persisting them.
- Why Do This on the Ingester:
- Only the Ingester has sufficient context (when chunks are merged/flushed) to control the timing and granularity of compression.
- Gzip compression is I/O-intensive, so there’s no need to waste resources on the traffic distribution layer (distributor).
- Compression is often tied to persistence (flushing), typically written synchronously to a cloud storage backend.
Typical Data Flow Overview
- Promtail sends logs to the Distributor.
- The Distributor performs consistent hashing on the tags, selects an Ingester, and forwards the log lines to it.
- The Ingester aggregates the log lines into chunks by stream. When writing chunks, compression is applied (typically using Snappy by default, but Gzip is also supported).
- When a chunk reaches a threshold, it is flushed to the backend storage (such as S3), where it is stored as compressed blocks.
Comments